
导读:汽车产业在芯片厂家的推动下进入了算力比拼时代,一场算力竞赛已经在各大芯片企业之间悄然兴起。殊不知高算力背后是高功耗和低利用率的问题日益突出,算力不可能一直提高。
事件相机的出现凭借自身极快的响应速度、减少无效信息、降低算力和功耗、高动态范围等优势对高算力芯片形成致命打击,它只需要传统算力芯片1%甚至0.1%的算力就可完美工作,功耗是毫瓦级。可以帮助自动驾驶车辆降低信息处理的复杂度、提高车辆的行驶安全,并能够在极亮或者极暗环境下正常工作。

一、像素与算力矛盾突出
需要处理的图像像素过多与芯片算力不足的矛盾,已经成为了当前制约自动驾驶发展的瓶颈之一。
当今自动驾驶领域所运用的视觉识别算法,基本上都基于卷积神经网络,视觉算法的运算本质上是一次次的卷积运算。这种计算并不复杂,本质上只涉及到加减乘除,也就是一种乘积累加运算。但这种简单运算在卷积神经网络中是大量存在的,这就对处理器的性能提出了很高的要求。
以ResNet-152为例,这是一个152层的卷积神经网络,它处理一张224*224大小的图像所需的计算量大约是226亿次,如果这个网络要处理一个1080P的30帧的摄像头,他所需要的算力则高达每秒33万亿次,十分庞大。
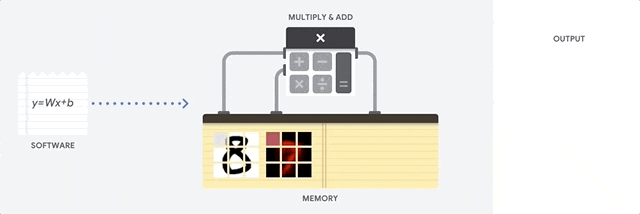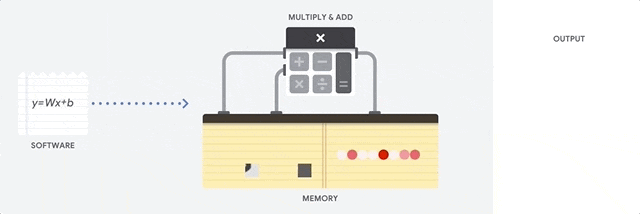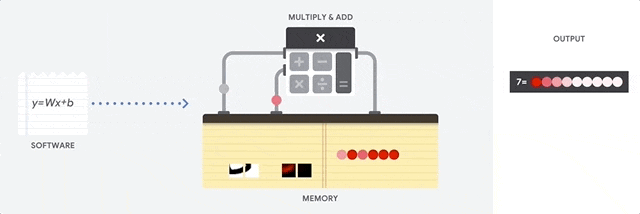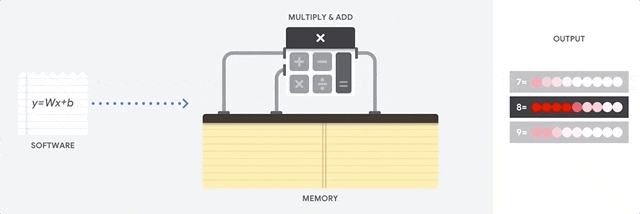
以当前典型的百度的无人车为例,计算平台约为800TOPS,其中1TOPS代表处理器可以每秒钟进行一万亿次操作。假设一个摄像头所需要的算力为33TOPS,更遑论无人车动辄配置十余个摄像头,以及多个激光雷达和毫米波雷达。
为了准确检测行人并预测其路径,芯片往往需要多帧处理,至少是10帧,也就是330毫秒。这意味着相关系统可能需要数百毫秒才能实现有效探测,而对于一辆以60公里每小时行进中的车辆来说,330毫秒的时间就能行驶5.61米。如果为了保证足够的安全,将帧数增加到每秒30帧,图像数据很可能让自动驾驶芯片不堪重负。
提高算力固然可以暂时解决问题,同时,算力的提高也伴随着功耗的提高,但在新能源的大背景下,分配给芯片的能量越多,续航能力就会受到越大的影响。算力与能耗正在逐渐成为自动驾驶发展的一对矛盾。
实际上自动驾驶领域99%的视觉数据在AI处理中是无用的背景。这就好像检测鬼探头,变化的区域是很小一部分,但传统的视觉处理仍然要处理99%的没有出现变化的背景区域,这不仅浪费了大量的算力,也浪费了时间。亦或者像在沙砾里有颗钻石,AI芯片和传统相机需要识别每一颗沙粒,筛选出钻石,但人类只需要看一眼就能检测到钻石,AI芯片和传统相机耗费的时间是人类的100倍或1000倍。
对于人类来讲,在静止的画面中注意到运动物体并不难。对于青蛙来说,它甚至只能看到运动的物体,对静止的背景画面视而不见。
针对生物这一特性,事件相机的出现,成功解决了自动驾驶中视觉处理的问题。
二、事件相机的工作原理
事件相机(event cameras)是一种生物启发的视觉传感器,以完全不同于标准相机的方式工作。事件相机不是以恒定速率输出强度图像帧,而是仅输出局部像素级亮度变化的相关信息。这些像素级亮度变化(称为事件)超过设定阈值时,事件相机以微秒级分辨率标记时间戳,并输出异步事件流。
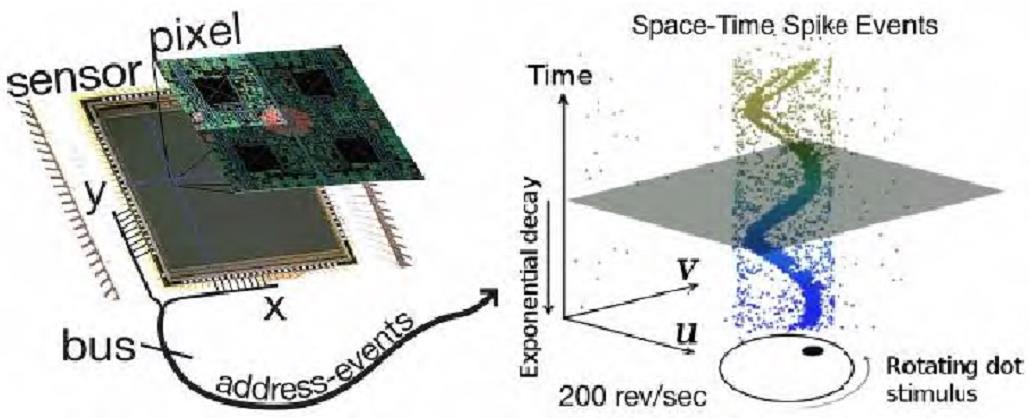
事件相机的灵感来自人眼和动物的视觉,也有人称之为硅视网膜。生物的视觉只针对有变化的区域才敏感,比如眼前突然掉下来一个物体,那么人眼会忽视背景,会将注意力集中在这个物体上,事件相机就是捕捉事件的产生或者说变化的产生。
在传统的视觉领域,相机传回的信息是同步的,所谓同步,就是在某一时刻t,相机会进行曝光,把这一时刻所有的像素填在一个矩阵里回传,一张照片就诞生了。一张照片上所有的像素都对应着同一时刻。至于视频,不过是很多帧的图片,相邻图片间的时间间隔可大可小,这便是我们常说的帧率(frame rate),也称为时延(time latency)。事件相机类似于人类的大脑和眼睛,跳过不相关的背景,直接感知一个场景的核心,创建纯事件而非数据。
事件相机的工作机制是,当某个像素所处位置的亮度发生变化达到一定阈值时,相机就会回传一个上述格式的事件,其中前两项为事件的像素坐标,第三项为事件发生的时间戳,最后一项取值为极性(polarity)0、1(或者-1、1),代表亮度是由低到高还是由高到低,也常被称作Positive or Negative Event,又被称作On or Off Event。
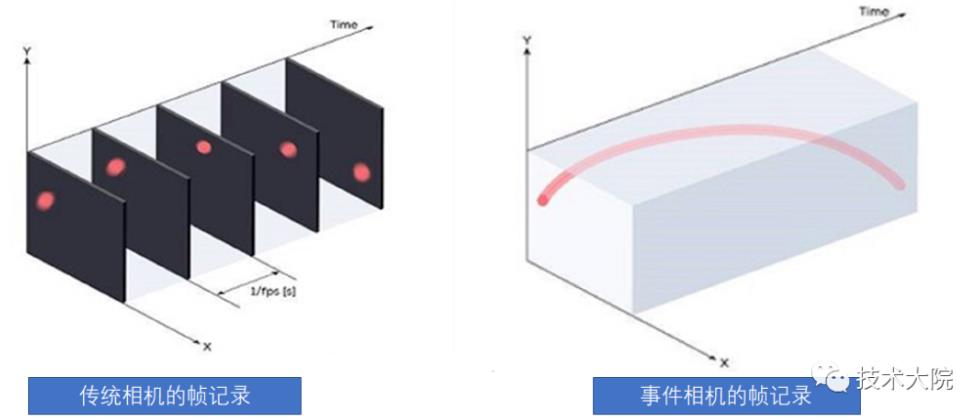
我们通过下图的小球实验可以更直观地发现:只要小球变化的时刻,就会产生事件流,而小球静止的时刻,就不会产生事件流。

图:事件相机与帧相机的输出信号对比
就这样,在整个相机视野内,只要有一个像素值变化,就会回传一个事件,这些所有的事件都是异步发生的(再小的时间间隔也不可能完全同时),所以事件的时间戳均不相同,由于回传简单,所以和传统相机相比,它具有低时延的特性,可以捕获很短时间间隔内的像素变化,延迟是微秒级的。
三、事件相机的优势
相对于传统相机,事件相机还有高帧率、低功耗、高动态范围等优点:
1)高帧率。实际上,所谓的“帧率”概念,对事件相机是不存在的。事件相机每个感光单元都可以异步的形式记录像素亮度变化,无需等待传统相机每秒30次的“曝光”时机。基于没有曝光的特点,事件相机的输出频率可以高达每秒100万次,远远超过每秒30次传统相机的帧率。
2)低时延。事件相机仅传输亮度变化,避免大量冗余数据的传输,因此能耗仅用于处理变化的像素。大多数事件相机的功耗约在 10 mW 级,而有部分相机原型的功耗甚至小于10 μW,远远低于传统基于帧的相机。
3)高动态范围。事件相机的动态范围高达140 dB,远远优于 60 dB 的帧相机。既能在光照条件良好的白天工作,也能在光线较暗的夜晚采集视场中的动态信息。这是由于事件相机每个像素的光感受器以对数方式独立工作,而非全局快门工作模式。因此,事件相机具有与生物视网膜相似的特性,其像素可以适应非常暗和非常亮的感光刺激。
在拍摄高速物体时传统相机会发生模糊(由于会有一段曝光时间),而事件相机几乎不会。再就是真正的高动态范围,由于事件相机的特质,在光强较强或较弱的环境下(高曝光和低曝光),传统相机均会“失明”,但像素变化仍然存在,所以事件相机仍能看清眼前的东西。

传统相机的动态范围是无法做宽的,因为放大器会有线性范围,照顾了低照度就无法适应强光,反过来适应了强光就无法顾及低照度。事件相机在目标追踪、动作识别等领域具备压倒性优势,尤其适合自动驾驶领域。
空中一个球的轨迹:

扔一个球,看看两种相机的轨迹记录:
事件相机的出现对高算力AI芯片是致命打击,它只需要传统高算力AI芯片1%甚至0.1%的算力就可完美工作,功耗是毫瓦级。事件相机基于流水线时间戳方式处理数据,而不是一帧帧地平面处理各个像素。传统卷积算法可能无用,AI芯片最擅长的乘积累加运算可能没有用武之地。为了准确检测行人并预测其路径,需要多帧处理,至少是10帧,也就是330毫秒。这意味着相关系统可能需要数百毫秒才能实现有效探测,而对于一辆以60公里每小时行进中的车辆来说,330毫秒的时间就能行驶5.61米,而事件相机理论上不超过1毫秒。
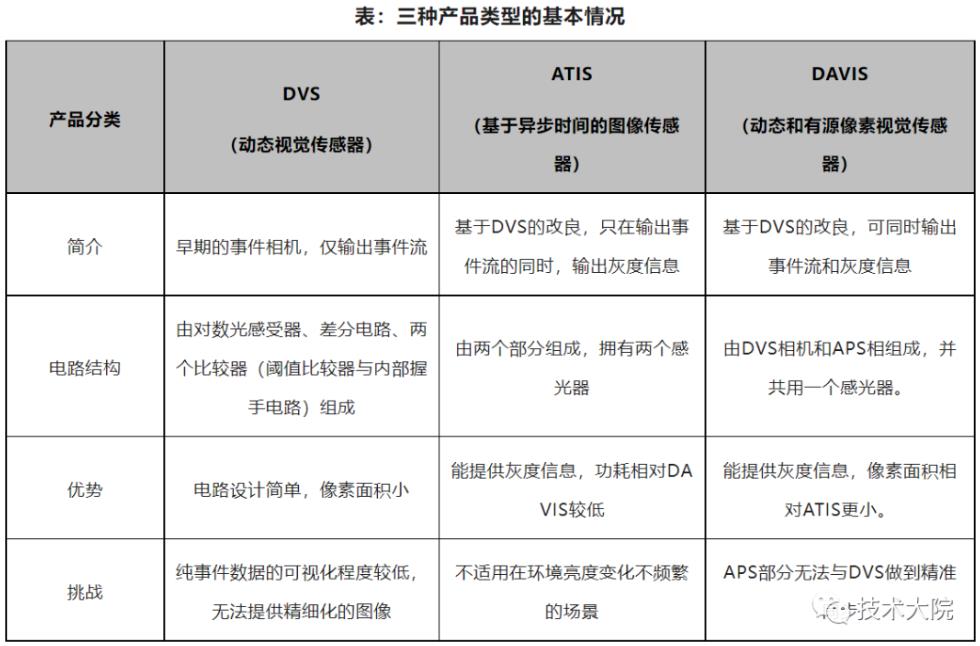
四、事件相机的产品分类
当前,市场上主流的事件相机产品主要为三类:DVS、ATIS以及DAVIS,它们都采用了差分型视觉采样模型。此外,也有一些其它类型的事件相机,比如CeleX、Vidar,但从商业化的进度来看,上述三类事件相机的商业化发展较快。
事件相机产业链的情况与传统帧相机几乎是相同的,主要包括上游是零部件供应商(镜头组零部件、胶合材料、图像传感器芯片等)、中游是模组供应商与系统集成商等、下游是主机厂。
产业链中的不同之处主要是在图像传感器芯片、算法软件,比如更适合事件相机的芯片是类脑芯片、更适合的算法则是脉冲神经网络。
第三代神经网络助力大规模应用
事件相机目前之所以没有大规模应用在自动驾驶领域,归根结底受限于神经网络算法。实际上,相机获取信息仅仅是第一步,后续事件相机信息的处理则是更为关键的一环。
如下图所示,传统相机的输出是一帧帧的静止图片,而事件相机则是一个个事件(Event)流。
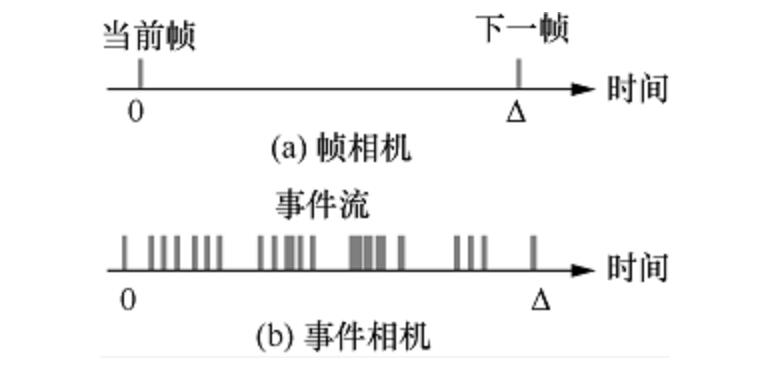
一般来说,目前的神经网络都专注于如何提取每帧静止图片中的行人、汽车等目标,如YOLO,resnet等算法。针对基于时间戳的事件流,目前尚无有效的算法进行目标识别。而事件流处理算法的缺失,与当前的神经网络结构是分不开的。
当前主流的神经网络被称为第二代人工神经网络,以精确的浮点运算为基础,缺失了在自然界中最重要的一个因素:时间。对于神经网络而言,输出的结果会和输入一一对应,任何时候输入相同的图片,神经网络都会输出一样的结果。
然而真实的大脑,是以这种浮点运算为基础的吗?显然不是,真实的大脑是以脉冲为基础的,以脉冲传递和处理信息。
这种以脉冲传递为基础的神经网络是脉冲神经网络(spiking neural network,SNN),被誉为第三代人工神经网络。基于脉冲神经网络结构设计的芯片也被称为类脑芯片。脉冲发生的时刻携带着重要信息,脉冲神经网络天然具备对时序信息处理的能力,这与事件相机基于时间戳的事件流输出十分吻合。
此外,脉冲神经网络还具有事件驱动、异步运算、极低功耗等特性。
1)事件驱动。在我们的大脑中,同一时刻大约有90%以上的神经元都是沉默的。也就是说,当没有事件输入的时候神经元是不活动的。这与事件相机的事件流输出十分契合,同时功耗也极大降低。
2)异步运算。脉冲神经网络不存在“主频”的概念。传统的计算机都需要一个时钟,以确保所有的操作都在时间步上进行,这个时钟的频率被称为主频。目前主流的计算机主频都达到每秒1GHz以上。然而,以IBM的神经态硬件TrueNorth为例,100Hz左右的脉冲发放率即可完成图像识别、目标检测等任务。当前通用的计算机基本是冯·诺依曼结构,这种结构下,随着CPU的运算速度远远超过内存的存取速度,已然形成难以逾越的计算瓶颈。然而,脉冲神经网络所有的内存和运算都体现在神经元的异步脉冲之中,有很大希望突破目前计算机运算能力瓶颈。
3)极低功耗。在2016年著名的人机围棋大战中,Google公司的AlphaGo系统每局围棋博弈的平均耗电费用高达3000美元。而作为脉冲神经网络架构的人脑,功率仅仅为20W左右。此前,有学者将目标检测中的经典算法YOLO进行脉冲化,在完成相同任务的情况下,功耗降低了280倍左右,同时速度提高了2.3到4倍。
总的来说,事件相机和脉冲神经网络的结合,正如人类用眼睛和大脑观察四周:自动忽略周围静止的事物,对突然出现的运动物体予以重点关注和运算。

总结
匹兹堡大学眼科教授、CMU机器人研究所兼职教授Ryad Benosman作为基于事件的视觉技术的奠基人之一,他认为:预计神经形态视觉(基于事件相机的计算机视觉)是计算机视觉的下一个方向。
基于图像相机的计算机视觉技术是非常低效的。Benosman将其比作中世纪城堡的防御系统:驻守在城墙周围的士兵从各个方向注视着接近的敌人。鼓手打着稳定的节拍,每敲一下,每个守卫就会大声喊出他们所看到的东西。在所有的呼喊声中,听到一个守卫在远处森林边缘发现敌人发出的声音会有多容易?
21世纪相当于鼓点的硬件是电子时钟信号,而卫兵是像素,每一个时钟周期都会产生一大批数据并必须进行检查,这意味着有大量的冗余信息和大量不必要的计算需要。
进入神经形态视觉。其基本理念是受生物系统工作方式的启发,检测场景动态的变化,而不是连续分析整个场景。在城堡比喻中,这将意味着让守卫保持安静,直到他们看到感兴趣的东西,然后喊出他们的位置,发出警报。在电子版本中,这意味着让单个像素决定它们是否看到了相关的东西。
Benosman教授说:像素可以自己决定他们应该发送什么信息,而不是获取系统信息,他们可以寻找有意义的信息,即特征。这就是与众不同之处。与固定频率的系统采集相比,这种基于事件的方法可以节省大量的功耗,并减少延迟。
现在的AI本质上还是一种蛮力计算,依靠海量数据和海量算力,对数据集和算力的需求不断增加,这显然离初衷越来越远,文明的每一次进步都带来效率的极大提高,唯有效率的提高才是进步,而依赖海量数据和海量算力的AI效率越来越低。
当前学术界已经掀起了对脉冲神经网络研究的热潮,随着人们对大脑认识的深入,以及国外的TrueNorth、SpiNNaker、Loihi和国内清华的天机芯(Tianjic)和浙大的达尔文等类脑芯片的研发。
小编坚信:事件相机与脉冲神经网络的完美结合在目标追踪、动作识别等领域具备压倒性优势,给自动驾驶行业带来新的突破。
来源:技术大院






