
导读:过去几年,人们对自动驾驶汽车产生了极大的热情。这的确在情理之中。自动驾驶汽车有望带来影响深远的好处:提高燃油效率、缩短行车时间、提高乘客体验和工作效率,让可能无法开车的老人和残疾人自由驾驶,以及最重要的提高道路安全。
如果你问:未来会发生什么?这谁知道?但有一点可以肯定:汽车行业的军备竞赛将快速升级。

尽管人们万分期待一款价格合理的全自动驾驶汽车,但技术复杂性、成本和监管挑战将自动驾驶汽车成为主流的时间一再推迟。智能化、自动化、移动计算平台……这些关键词承载着我们对未来汽车的想象。汽车制造行业的所有参与者正推动着这场变革。
一、如火如荼的算力竞赛
曾几何时,博世、大陆、德尔福、采埃孚……这些国际巨头一级供应商是令自主品牌车企仰望的存在。它们把控着整车上最核心的技术,拥有着绝对的议价能力,甚至他们的开发进度直接决定了车型的研发周期。从动力总成到底盘,在这些传统汽车电子产品上,巨头Tier 1们拥有无可匹敌的竞争力。
而到了自动驾驶时代,巨头Tier 1们的这套打法渐渐开始失效了,因为它们露出了一个共同的破绽——算法能力不足。
ADAS这两年进入高光时刻,除了云端居垄断地位的英伟达,华为、高通等巨头的入局,亦或地平线、黑芝麻的竞争,甚至寒武纪跑步进入都引起了业界极大关注。算力的不断提升,也让各大车企对进入算力的“军备竞赛”产生焦虑。
这场算力“军备赛”的背后,最为直接的驱动力在于,车企原有的计算平台(芯片)的算力不足问题逐步凸显:
一方面,各大车厂正在全力备战高级自动驾驶的量产,多传感器融合已经成为高阶自动驾驶应对复杂场景与安全冗余的必然趋势。处理这些数据需要非常强大的计算能力,L2级自动驾驶的算力要求大概是10+TOPS,但是到了L4/L5级自动驾驶算力则需要达到1000+TOPS,同比翻了100倍
另一方面,包括安波福、博世等Tier1巨头,以及大众、宝马等车企开始探索新型的电子电气架构,传统分布式的汽车电子电气架构正在向域集中式架构演进,从而带动了高性能大算力芯片的需求急剧上涨
现阶段,汽车产业在芯片厂家的推动下进入了算力比拼时代:
英伟达最新一款智能汽车和自动驾驶汽车芯片组——DRIVE Atlan,单颗芯片的算力能够达到1000TOPS,将应用于L4及L5级别自动驾驶
特斯拉推超级计算机Dojo,使用720个80GB版本的8x A100节点构建的超级计算机,总算力达到了1.8EFLOPS(EFLOPS:每秒千万亿次浮点运算),有10PB的存储空间,读写速度为1.6TBps
黑芝麻华山二号A1000 Pro,算力达到106(INT8)—196TOPS(INT4),单颗芯片可以支持高级别自动驾驶功能。
地平线推出面向高级别自动驾驶的征程5,算力最高达到128TOPS,支持16路高清摄像头,实际性能超过特斯拉FSD。
寒武纪跑步进入自动驾驶领域,将发布一款算力超200TOPS智能驾驶芯片。

一场算力竞赛已经在各大芯片企业之间悄然兴起,追求TOPS算力真的有那么重要吗?是不是堆叠芯片的算力,就能达到目的了?业内似乎进入了“唯算力论”的误区。
二、算力堆不出自动驾驶
不可否认,随着ADAS、自动驾驶技术的兴起,以及软件定义汽车的逐步深入,智能汽车对于计算能力和海量数据处理能力等的需求暴增,传统汽车的芯片“堆叠”方案已经无法满足自动驾驶的算力需求。
作为现代科技工业中的集大成者和数字经济基础设施的芯片,汇集了最复杂、最尖端、最精密的基础性技术,以及高端人才和资金,无疑是未来争夺的焦点。
芯片最终是为车企的车载计算平台服务的。行业需要思考一个问题是:在“软件定义汽车”的情况下,解决智能驾驶系统计算平台的支撑问题,是否只能通过芯片算力堆叠来实现?是不是唯芯片算力马首是瞻呢?显然不是。
提升硬件很重要,但不能陷入“唯算力论”的怪圈。
我们说“数据是生产资料”,而提供处理数据的芯片是工具,不可能工具反客为主成为核心。工具是必备的,但是更重要的核心是跑在上面的软件。
芯片就是软件的舞台,衡量芯片优劣的标准,要看芯片之上的软件能否最大化地发挥作用。当然不是说算力不重要,算力和软件之间需要有效匹配。两款相同算力的芯片比较,能让软件运行得更高效的芯片才是“好芯片”。
决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,还有实际运行频率(即供电电压或温度),以及算法的batch尺寸。谷歌第一代TPU,理论值为90TOPS算力,最差真实值只有1/9,也就是10TOPS算力,因为第一代内存带宽仅34GB/s
第二代TPU下血本使用了HBM内存,带宽提升到600GB/s(单一芯片,TPU V2板内存总带宽2400GB/s)。
最新的英伟达的A100使用40GB的2代HBM,带宽提升到1600GB/s,比V100提升大约73%。
特斯拉是128 bitLPDDR4-4266,内存的带宽:2133MHz*2DDR*128bit/8/1000=68.256GB/s。比第一代TPU略好(这些都是理论上的最大峰值带宽)其性能最差真实值估计是2/9。也就是大约8TOPS
为什么会这样?这就牵涉到MAC计算效率问题。
如果你的算法或者说CNN卷积需要的算力是1TOPS,而运算平台的算力是4TOPS,那么利用效率只有25%,运算单元大部分时候都在等待数据传送,特别是batch尺寸较小时候,这时候存储带宽不足会严重限制性能。但如果超出平台的运算能力,延迟会大幅度增加,存储瓶颈一样很要命。效率在90-95%情况下,存储瓶颈影响最小,但这并不意味着不影响了,影响依然存在。然而平台不会只运算一种算法,运算利用效率很难稳定在90-95%。这就是为何大部分人工智能算法公司都想定制或自制计算平台的主要原因,计算平台厂家也需要推出与之配套的算法,软硬一体,实难分开。
自动驾驶之争实质上一场软硬平台之战。单颗芯片算力TOPS是关键指标,但并非唯一,自动驾是一个复杂系统,需要车路云边协同。所以它的较量除了芯还有软硬协同还有平台以及工具链等等。
自动驾驶芯片的竞争壁垒在于算力利用率和可用性。芯片厂商根据软件提供底层的硬件支持,在整车设计里提供的价值更高,在供应链里的议价能力更强。与Tesla自研汽车中央计算设备相比,软硬件开放式平台的解决方案潜力大。
以PC时代的WinTel联盟为例,在WinTel架构下,Intel芯片和Windows操作系统高度协同,最终才能产生垄断市场份额的效果,缺一不可。
前百度总裁陆奇博士提出过“母生态”概念,智能汽车将是继PC、智能手机之后更大的母生态,也是中国汽车行业和科技产业最大的机遇所在。而且,芯片所在的科技产业逐步走向成熟的标志之一就是形成完整的生态。
作为车企来说,还有一个芯片的成本问题。算力有多重要,就有多昂贵。据有关机构评估下来,做一颗车规级的AI芯片,就是L2+、L3的 AI芯片大概成本在5亿到7亿美金之间,时间是在2~3年。
现在算力的军备竞赛是已经掀起来了,但是芯片的算力本质上对于智能驾驶系统还是必要不充分的条件,现在大家更多提的算力是峰值算力。我们经常会看到一个优化程度不好的芯片宣称有10TOPS算力,实际跑出来的应用等效只有3~4TOPS的算力。
现在的一种倾向是“L4硬件+L2软件”,先硬件“预埋”以达标或者超标,软件上慢慢积累。但是反过来说,这是不是一种浪费?恐怕,还是要对每一个TOPS都要精打细算地使用。
芯片算力的无限膨胀和硬件预埋不会是未来的趋势,硬件也需要匹配实际,有业内人士就说过:特别是在SoC上,我们需要精准高效的算力来适配电子电气架构的变革。
此外,车企面对的消费端是不是立刻就需要那么高端的算力呢?也不见得。
自动驾驶算力主要是体现在感知层面的融合,对于L3 100~200已经够了,对于L4可能需要200~300,更关键是怎么用算力,不是说越多越好,如果要做1000,其实是没有必要的,并且高算力背后是高功耗和低利用率的问题。
三、高功耗、低利用率日益突出
算力也不能说无限增长,芯片PPA(功耗、成本和面积)都是很要命的。
这是因为,对于车载AI芯片来说,算力指标重要,能效比更重要。在传统芯片行业,PPA是最经典的性能衡量指标。而现在出于自动驾驶对算力的追求,业界还是把“峰值算力”当作衡量AI芯片的主要指标的话,就导致了一种“唯算力论”的偏颇。
评价一颗芯片的维度来讲,其实有这样几个指标:
性能,即所谓的算力、成本、功耗、易用性,或者是叫易开发性、同构性,就是芯片平台对其他系统的兼容性
功耗和利用率是两个概念:
功耗是如何去平衡整个板载级、芯片级层面功耗。但是对于芯片公司来讲,芯片的功耗不仅包括AI部分,因为目前很多芯片都是多核异构的。
利用率是AI算法优化利用算力的能力。跟每一家神经网络的架构是有关系的,对于有的大通量、并行计算,它的利用率一定是有天花板的
在ASIC方案中,每一家的架构是不一样的,算法也不尽相同
对于同一个算法在不同的芯片平台上去跑,算子库越丰富,算法跨平台移植的效果就会越好,所以ASIC的利用率一定比GPU要高。以英伟达的芯片为例,它GPU的功耗是最高的。Orin、Xavier的利用率基本上是30%,怎样优化基本都是30%。不同于英伟达的GPU方案,高通、mobileye、华为,包括国内这些创业公司都走的是ASIC路线。ASIC芯片针对不同的神经网络模型去优化,基本上可以做到60%~80%之间,好一点的可能会做到80%再高一些。
在手机领域,英伟达基本上败给了高通,在PC领域,英伟达败给了Intel。在专业芯片领域,英伟达其实并没有太多的成功案例和经验,其实本质上与它整个GPU的生态有关系。当前来看,英伟达所有的开发工具,包括它的算子库丰富程度,都是非常好的。客户用英伟达的芯片,除了功耗和利用率之外,别的都特别顺手。所以我们现在看到英伟达能够如日中天的在整个行业里面存在,但是未来在市场中它肯定会往下降。
从利用率、功耗这些关键指标上来讲,笔者预测:高通可能会在三年之后,2024年2025年这个期间抢走很大一个市场。同时这也是国内初创企业的一个机会,从这个用户痛点着手,拿下市场。地平线提出了一个新的方法MAPS(Mean Accuracy-guaranteed Processing Speed,在精度有保障范围内的平均处理速度),用以评估芯片的AI真实性能。而在业内没有统一的测评标准情况下,目前还只能算是一家之言。

不过功耗方面地平线还是有巨大优势的。以地平线2020年最先商用量产的征程2芯片为例,它搭载自主研发的计算架构BPU2.0(Brain Processing Unit),可提供超过4TOPS的等效算力,典型功耗仅2瓦,而且,每TOPS的AI能力输出可达同等算力GPU的10倍以上。
对于车企来说,在最高性能模式下,如果自动驾驶控制器的芯片功耗级别较高,即便其自身性能强劲,但也会引发某些不可预知的隐患,如发热量成倍增加,耗电率成倍增加,这些结果对于智能电动车来说毫无疑问是颗“雷”。
四、高算力AI芯片的致命一击
当今自动驾驶领域所运用的视觉识别算法,基本上都基于卷积神经网络,视觉算法的运算本质上是一次次的卷积运算。这种计算并不复杂,本质上只涉及到加减乘除,也就是一种乘积累加运算。但这种简单运算在卷积神经网络中是大量存在的,这就对处理器的性能提出了很高的要求。
以ResNet-152为例,这是一个152层的卷积神经网络,它处理一张224*224大小的图像所需的计算量大约是226亿次,如果这个网络要处理一个1080P的30帧的摄像头,他所需要的算力则高达每秒33万亿次,十分庞大。
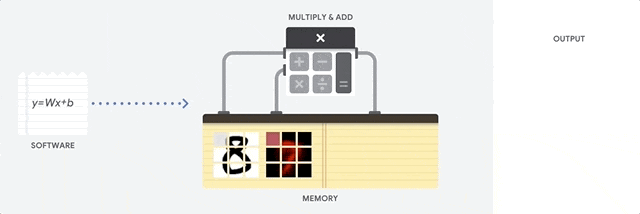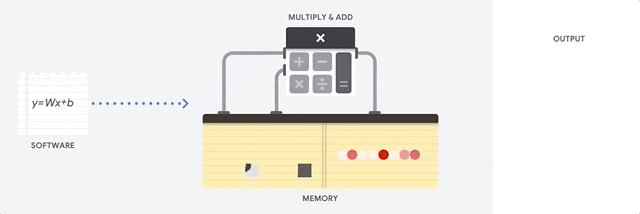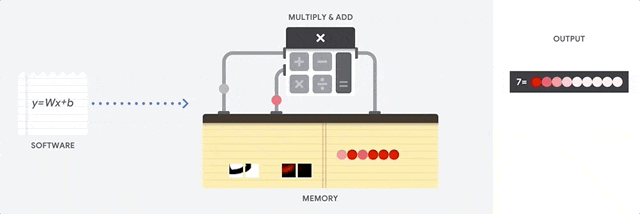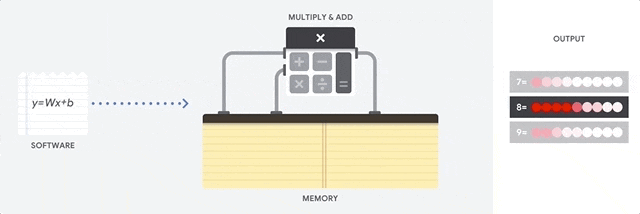
实际上自动驾驶领域99%的视觉数据在AI处理中是无用的背景。这就好像检测鬼探头,变化的区域是很小一部分,但传统的视觉处理仍然要处理99%的没有出现变化的背景区域,这不仅浪费了大量的算力,也浪费了时间。亦或者像在沙砾里有颗钻石,AI芯片和传统相机需要识别每一颗沙粒,筛选出钻石,但人类只需要看一眼就能检测到钻石,AI芯片和传统相机耗费的时间是人类的100倍或1000倍。
事件相机的工作机制是,当某个像素所处位置的亮度发生变化达到一定阈值时,相机就会回传一个上述格式的事件,其中前两项为事件的像素坐标,第三项为事件发生的时间戳,最后一项取值为极性(polarity)0、1(或者-1、1),代表亮度是由低到高还是由高到低,也常被称作Positive or Negative Event,又被称作On or Off Event。
就这样,在整个相机视野内,只要有一个像素值变化,就会回传一个事件,这些所有的事件都是异步发生的(再小的时间间隔也不可能完全同时),所以事件的时间戳均不相同,由于回传简单,所以和传统相机相比,它具有低时延的特性,可以捕获很短时间间隔内的像素变化,延迟是微秒级的。
事件相机的灵感来自人眼和动物的视觉,也有人称之为硅视网膜。生物的视觉只针对有变化的区域才敏感,比如眼前突然掉下来一个物体,那么人眼会忽视背景,会将注意力集中在这个物体上,事件相机就是捕捉事件的产生或者说变化的产生。在传统的视觉领域,相机传回的信息是同步的,所谓同步,就是在某一时刻t,相机会进行曝光,把这一时刻所有的像素填在一个矩阵里回传,一张照片就诞生了。一张照片上所有的像素都对应着同一时刻。至于视频,不过是很多帧的图片,相邻图片间的时间间隔可大可小,这便是我们常说的帧率(frame rate),也称为时延(time latency)。事件相机类似于人类的大脑和眼睛,跳过不相关的背景,直接感知一个场景的核心,创建纯事件而非数据。
除了冗余信息减少和几乎没有延迟的优点外,事件相机的优点还有由于低时延,在拍摄高速物体时传统相机会发生模糊(由于会有一段曝光时间),而事件相机几乎不会。再就是真正的高动态范围,由于事件相机的特质,在光强较强或较弱的环境下(高曝光和低曝光),传统相机均会“失明”,但像素变化仍然存在,所以事件相机仍能看清眼前的东西。
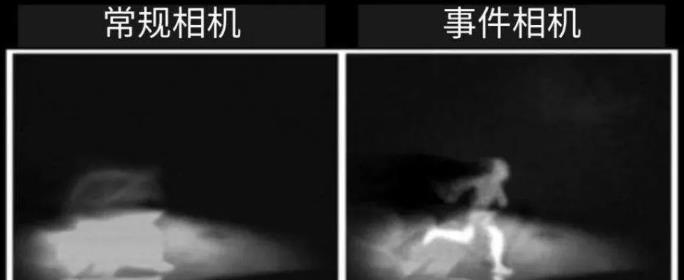
传统相机的动态范围是无法做宽的,因为放大器会有线性范围,照顾了低照度就无法适应强光,反过来适应了强光就无法顾及低照度。事件相机在目标追踪、动作识别等领域具备压倒性优势,尤其适合自动驾驶领域。
空中一个球的轨迹:

扔一个球,看看两种相机的轨迹记录:
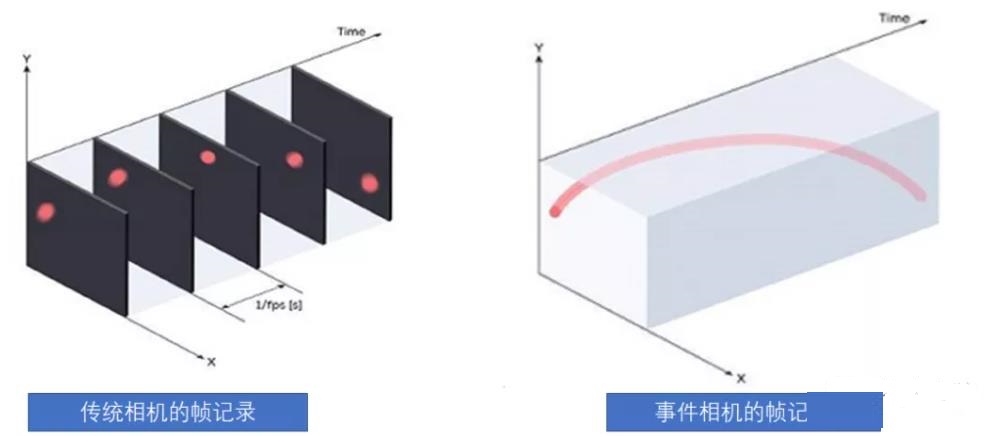
事件相机的出现对高算力AI芯片是致命打击,它只需要传统高算力AI芯片1%甚至0.1%的算力就可完美工作,功耗是毫瓦级。事件相机基于流水线时间戳方式处理数据,而不是一帧帧地平面处理各个像素。传统卷积算法可能无用,AI芯片最擅长的乘积累加运算可能没有用武之地。为了准确检测行人并预测其路径,需要多帧处理,至少是10帧,也就是330毫秒。这意味着相关系统可能需要数百毫秒才能实现有效探测,而对于一辆以60公里每小时行进中的车辆来说,330毫秒的时间就能行驶5.61米,而事件相机理论上不超过1毫秒。
五、技术路线展望
中国自动驾驶正在显示出三条主流技术路线:
特斯拉路线:纯视觉路线,特斯拉芯片+特斯拉算法+视觉传感器
英伟达路线:融合感知路线,英伟达芯片+多种传感器+OEM自研算法
华为路线:融合感知路线,华为芯片+华为算法+多种传感器
特斯拉目前最顶配的FSD,8个摄像头的分辨率只有130万像素,就已经需要144TOPS的算力,而目前英伟达的自动驾驶试验车型用的摄像头已经是800万像素,因此1000TOPS的算力是必须的,如此大的算力不仅带来高成本,还有高热量。除非能挖矿,否则是太浪费了。
今年1月初,瑞典初创公司Terranet宣布斩获了来自汽车产业巨头戴姆勒梅赛德斯奔驰的Voxelflow原型采购订单,订单价值31000欧元。这笔采购订单是Terranet和戴姆勒于2020年10月签署的谅解备忘录(MoU)的延续,双方的谅解备忘录涉及ADAS和防撞解决方案的原型验证、产品开发和产业化。下一步是将VoxelFlow集成到奔驰的测试车辆中。实际Terranet的核心是基于事件的图像传感器(Event-based Camera Sensor,或Event-driven Camera Sensor)。
事件相机仍然无法取代激光雷达或双目系统,因为它无法提供深度信息,因此事件相机必须配合激光雷达才能实现完美的3D感知。VoxelFlow技术能够凭借很低的算力,以极低的延时对动态移动物体进行分类。每秒可以生成1000万个3D点云,提供没有运动模糊的快速边缘检测。基于事件的传感器的超低延时性能,能够确保车辆及时应对“鬼探头”问题,采取紧急制动、加速或绕过突然出现在车辆后方的物体以避免碰撞事故。
现在的AI本质上还是一种蛮力计算,依靠海量数据和海量算力,对数据集和算力的需求不断增加,这显然离初衷越来越远,文明的每一次进步都带来效率的极大提高,唯有效率的提高才是进步,而依赖海量数据和海量算力的AI则完全相反,效率越来越低,事件相机才是正确的方向。
来源:技术大院






